
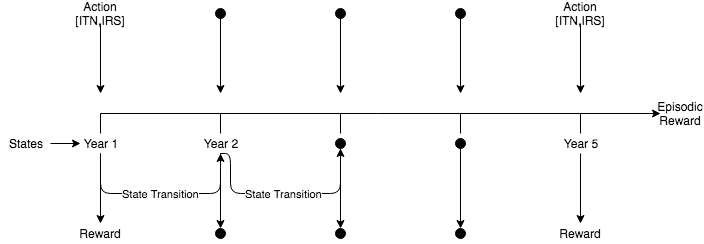
State
$S \in \{1,2,3,4,5\}$
Action
$A_S = [a_{ITN},a_{IRS}]$
where $a_{ITN} \in [0,1]$ and $a_{IRS} \in [0,1]$
Reward
$R_{\pi} \in (- \infty,\infty)$

In [1]:
import numpy as np
from collections import defaultdict
import random
# !pip3 install git+https://github.com/slremy/netsapi --user --upgrade
from netsapi.challenge import *
Bandit Randomized Probability Matching Agent Code:
In [2]:
class BanditRPM(object):
def __init__(self,env):
self.env = env
self.action_resolution = 0.1
self.actions = self.actionSpace()
self.ActionValue = {}
self.init = (2,5)
for key in self.actions:
self.ActionValue[key] = self.init
def actionSpace(self):
x = np.arange(0,1+self.action_resolution,self.action_resolution)
y = 1-x
x = x.reshape(len(x),1)
y = y.reshape(len(y),1)
xy = np.concatenate((x, y), axis=1)
xy = xy.round(2)
xy = [tuple(row) for row in xy]
return xy
def choose_action(self):
"""
Use Thompson sampling to choose action. Sample from each posterior and choose the max of the samples.
"""
samples = {}
for key in self.ActionValue:
samples[key] = np.random.beta(self.ActionValue[key][0], self.ActionValue[key][1])
max_value = max(samples, key=samples.get)
return max_value
def update(self,action,reward):
"""
Update parameters of posteriors, which are Beta distributions
"""
a, b = self.ActionValue[action]
a = a+reward/100
b = b + 1 - reward/100
a = 0.001 if a <= 0 else a
b = 0.001 if b <= 0 else b
self.ActionValue[action] = (a, b)
def train(self):
for _ in range(20): #Do not change
self.env.reset()
while True:
action = self.choose_action()
nextstate, reward, done, _ = self.env.evaluateAction(list(action))
self.update(action,reward)
if done:
break
def generate(self):
best_policy = None
best_reward = -float('Inf')
self.train()
best_policy = {state: list(self.choose_action()) for state in range(1,6)}
best_reward = self.env.evaluatePolicy(best_policy)
print(best_policy, best_reward)
return best_policy, best_reward
Run the EvaluateChallengeSubmission Method with your Agent Class
In [ ]:
EvaluateChallengeSubmission(ChallengeSeqDecEnvironment, BanditRPM, "BanditRPM_submission.csv")